Storing data as Knowledge Graphs
1989, CERN Switzerland
Tim Berners-Lee
inventor of the World Wide Web
The Web's foundational ideas
-
Data is linked to each other
Across heterogeneous systems (decentralized)
-
Browser programs
Visualises data and helps users navigating the Web
-
Everyone can read data
Using Web browsers
-
Open standards
Anyone can implement tools (browsers, ...) on top of it
1990-... World-wide adoption
Not just for researchers anymore
The Web is a global information space
a.k.a. The World Wide Web (WWW)
Mostly used by humans through Web browsers
Web is focused on humans
-
Web pages show information
Visualized using Web browsers
-
Clicking on links
To discover new information
-
Search information
Using search engines such as Google, Bing, ...
Achieving tasks requires manual effort
-
Will it rain next week?
- Find a weather prediction website
- Select your location
- Navigate to next week
-
Book a trip for a group of people
- Comparing agendas
- Comparing interests: nature, musea, ...
- Regional temperatures
- Geopolitical status
- ...
What if intelligent agents
could do these tasks for us?
I Have a Dream
A Web where intelligent
agents are able to achieve
our day-to-day tasks.
2001
The Semantic Web will bring structure to the meaningful content of Web pages, creating an environment where software agents roaming from page to page can readily carry out sophisticated tasks for users.
The dream: Getting there step by step
2015: Agents are being introduced that can perform simple tasks

 Google Assistant, Alexa, Siri, ...
Google Assistant, Alexa, Siri, ...
How do these agents work?
→ Execute Queries over Knowledge Graphs
Query = Structured Question
Knowledge Graph = Structured information
→ Structured questions over structured information
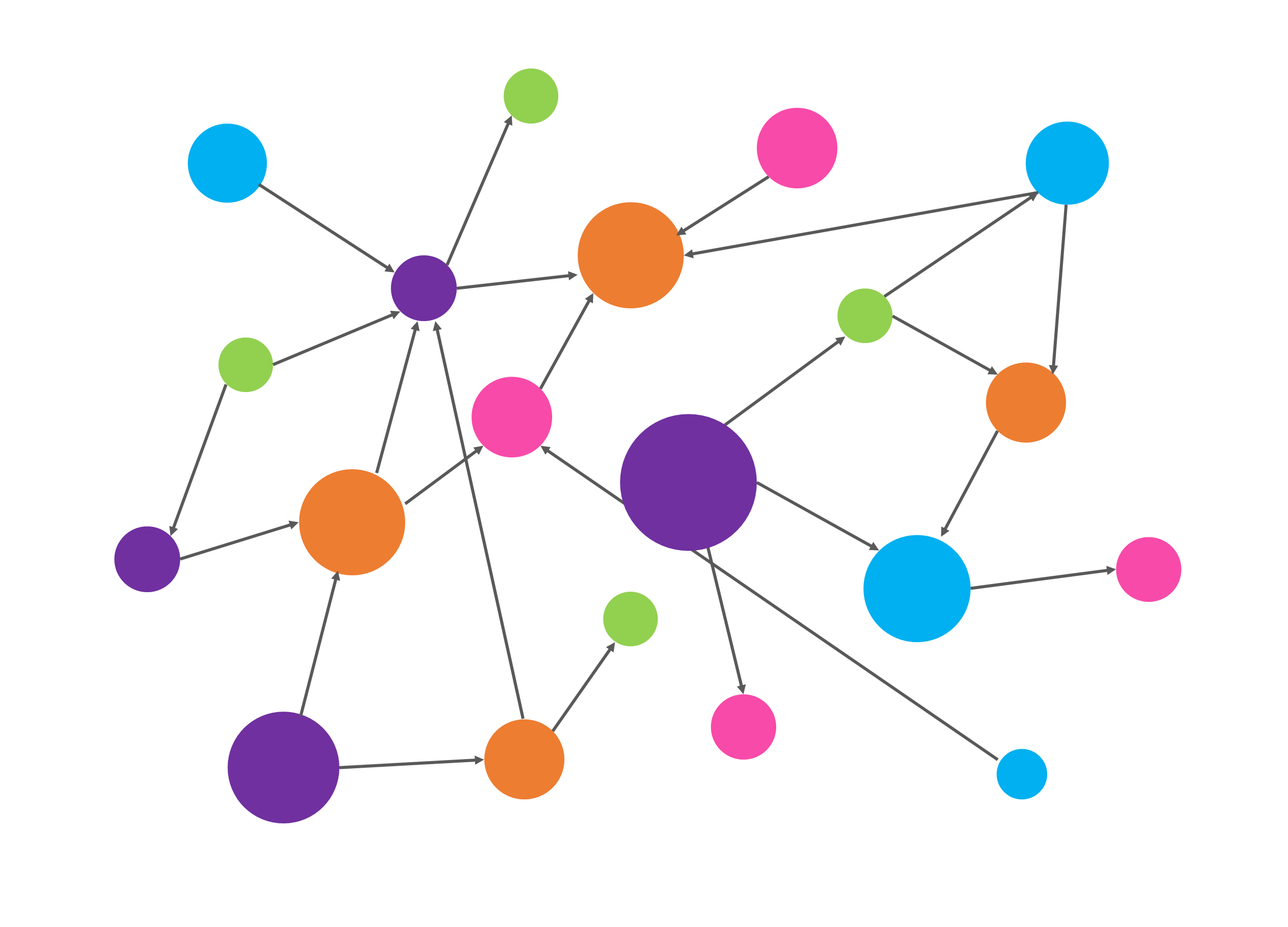
A Knowledge Graph is
a collection of structured information
Semantic Web technologies
-
RDF
Standard for representing and exchanging graph data
Knowledge Graphs are collections of such graph data
-
SPARQL
Standard for querying over RDF data
Generative AI models
2022: LLMs offer human-like conversations based on crawled Web data
Differences to Knowledge Graphs:
- Adaptive understanding of unstructured data
- Inconsistent answers and hallucinations
- Black box
RDF enables data exchange on the Web
-
RDF
Resource Description framework
-
Recommended by W3C since 1999
-
Recommended by W3C since 2014
-
Upcoming in 2025
Facts are represented as RDF triples


Multiple RDF triples form RDF datasets
:Alice :knows :Bob .
:Alice :knows :Carol .
:Alice :name "Alice" .
:Bob :name "Bob" .
:Bob :knows :Carol .
RDF Resources are identified by IRIs
https://example.org/Alice
-
IRI
Internationalized Resource Identifier
-
Global identifiers
Can be used by different data sources → interlinking!
-
IRIs can be URLs
A URL is an IRI that can be dereferenced (e.g. looked up in Web browsers).
Allows additional information to be looked up for a resource.
Multiple syntaxes exist for RDF
Turtle
PREFIX dbr: <http://dbpedia.org/resource/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
dbr:Alice foaf:knows dbr:Bob .
dbr:Alice foaf:name "Alice" .
JSON-LD
{
"@context": {
"dbr": "http://dbpedia.org/resource/",
"foaf": "http://xmlns.com/foaf/0.1/"
},
"@id": "dbr:Alice",
"foaf:knows": "dbr:Bob",
"foaf:name": "Alice"
}
SPARQL querying over RDF datasets
- SPARQL: language to read and update RDF datasets via declarative queries.
-
Different query forms:
SELECT: selecting values in tabular form → focus of this presentationCONSTRUCT: construct new triplesASK: check if data existsDESCRIBE: describe a given resourceINSERT: insert new triplesDELETE: delete existing triples
Specification: https://www.w3.org/TR/sparql-query/
Find all artists born in York
| name | deathDate |
| Albert Joseph Moore | |
| Charles Francis Hansom | 1888 |
| David Reed (comedian) | |
| Dustin Gee | |
| E Ridsdale Tate | 1922 |
How do query engines process a query?
RDF dataset + SPARQL query
↓
...
↓
query results
How do query engines process a query?
RDF dataset + SPARQL query
↓
SPARQL query processing
↓
query results
Basic Graph Patterns enable graph pattern matching
Query results representation
-
Solution Mapping
Mapping from a set of variable labels to a set of RDF terms.
-
Solution Sequence
A list of solution mappings.
1 solution sequence with 3 solution mappings:
| name | birthplace |
| Bob Brockmann | http://dbpedia.org/resource/Louisiana |
| Bennie Nawahi | http://dbpedia.org/resource/Honolulu |
| Weird Al Yankovic | http://dbpedia.org/resource/Downey,_California |
Steps in SPARQL query processing
-
1. Parsing
Transform a SPARQL query string into an algebra expression
-
2. Optimization
Transform algebra expression into a query plan
-
3. Evaluation
Executes query plan to obtain query results
Publishing Knowledge Graphs as SPARQL Endpoints
SPARQL endpoint: API that accepts SPARQL queries, and replies with results.
-
Most popular way to publish Knowledge Graphs
Alternatives are data dumps and Linked Data Documents
-
Very powerful
Very complex queries can be formulated with SPARQL
-
Power comes with a cost
SPARQL endpoints can require very powerful servers
Popular biological SPARQL endpoints
Federation over multiple SPARQL endpoints
Data across multiple datasources can be joined in a single query
-
Joins Uniprot and Rhea
-
Joins Uniprot, Rhea, and ChEMBL
Conclusions
-
Biological Knowledge Graphs use (Semantic) Web technologies
RDF, SPARQL, …
-
Knowledge Graphs can be interlinked
Thanks to RDF's global identifiers
-
Federated querying
Combining data across multiple Knowledge Graphs
Complex queries can be slow