A need for Evolving Knowledge Graphs
-
Some knowledge evolves over time
- Biomedical information → tracking diseases
- Concept drift → discovering the true meaning of old books
- Highway sensors → avoiding traffic jams
-
Semantic Web state of research by data volatility (estimation)

How to store and query
evolving knowledge graphs
on the Web?
I focus on four challenges
Experimentation requires representative evolving data.
Chapter 2: Generating Synthetic Evolving DataIndexing evolving data involves a trade-off between
storage efficiency and lookup efficiency.
Chapter 3: Storing Evolving DataWeb interfaces are highly heterogeneous.
Chapter 4: Querying a heterogeneous WebPublishing evolving data via a queryable interface
involves continuous updates to clients.
Chapter 5: Querying Evolving Data
Generating Synthetic Evolving Data
"Can population distribution data be used to generate realistic synthetic public transport networks and scheduling?"
 Contributions:
Contributions:
- Mimicking algorithm for generating public transport networks
- Open-source implementation: PoDiGG
- Realism and performance evaluation
Storing Evolving Data
"How can we store RDF archives to enable efficient
versioned triple pattern queries with offsets?"
 Contributions:
Contributions:
- Versioned storage mechanism and triple pattern query algorithms
- Open-source implementation: OSTRICH
- Performance evaluation
Querying a heterogeneous Web
Solving the need for flexible software in Web query research
 Contributions:
Contributions:
- Modular actor-mediator-bus architecture
- Open-source implementation: Comunica
- Performance evaluation
Querying Evolving Data
"Can clients use volatility knowledge to perform more efficient continuous SPARQL query evaluation by polling for data?"
 Contributions:
Contributions:
- Publication approach and continuous client-side query algorithm
- Open-source implementation: TPF Query Streamer
- Performance evaluation
Overview
How to store and query evolving knowledge graphs on the Web?
Generating Synthetic Evolving Data
Storing Evolving Data
Querying a Heterogeneous Web
Querying Evolving Data
→ Publishing and querying of evolving knowledge on the Web.
0.1. Issues with quality of manuscript
Typesetting, references, font spacing, positioning of titles, code listings cut off, ...
- Alternative to LaTeX/Word
- MarkDown → HTML/PDF (with RDFa)
- Used extensively to write papers in our lab (and others)
- As an experiment, I tried it for this PhD manuscript
- Root problem: bad CSS print support in browsers
- Canonical version: https://phd.rubensworks.net/
0.2. Relationship to other papers
Chronological overview of my main publications
0.3. Open challenges
- Different storage trade-offs
- Incorporating the meaning of data during versioned querying
- Knowledge Graph volatility
- Standardization efforts
- Large-scale decentralization
0.4. Research Answer
How to store and query evolving knowledge graphs on the Web?
- Type of data: Low volatility (order of minutes or slower)
- Server interface: Low-cost polling-based interface
- Server storage: Hybrid snapshot/delta/timestamp-based storage system
- Client: Intelligent hypermedia-enabled polling query engine
- Experimentation: Using synthetic public transport datasets
→ Decentralized publishing and querying of evolving knowledge at a low cost.
1.1. Mention of sensors in motivation may be misleading
In hindsight, I agree.
However, still relevant because:
- Sensors ∈ stream processing.
- Line between stream processing and versioning is fuzzy → there is overlap.
- CityBench: real-world sensors Aarhus (Denmark) with observation / 5 minutes.
2.1. Can the approach be generalized?
Yes, thanks to modularity of phases (region, stops, edges, routes, trips)
Generalization is possible on 2 levels:
-
Generating public transport networks without population distributions
But with e.g. light polution
-
Generate something else than public transport networks
E.g. reuse edge generator for synthetic artiries in biomedical domains
2.2. Is the generator deterministic?
Yes, using random seed
- Generators accept
seed (integer) parameter.
- Random values generated using this seed. (example)
- No multithreading
- Fully deterministic (assuming no external exceptions)
2.3. Value of coherence evaluation
Distance functions are indeed more valueable, but coherence is still important.
Most existing benchmarks are too structured:
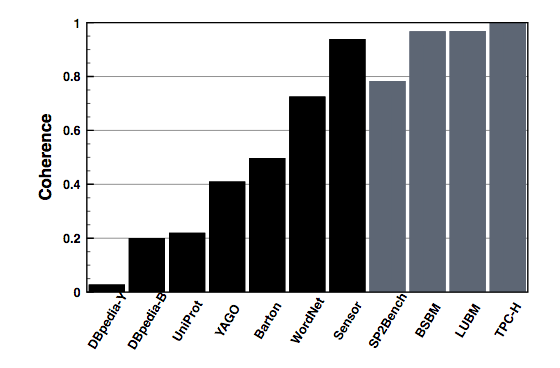
Duan et al. "Apples and Oranges: A Comparison of RDF Benchmarks and Real RDF Datasets"
My goal: proving that PoDiGG does not suffer from this problem.
2.4.1. Equation 5: Normalization is surprising
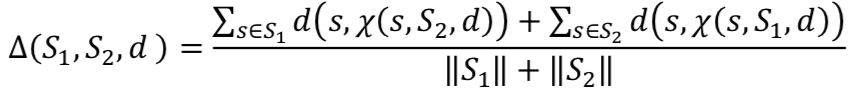
Equation 5 (page 48): Generic function for calculating distance between 2 sets of elements
- Goal was to normalize to 0-1 range.
- Denominator too small.
- Denominator should be multiplied with max distance between S1 and S2.
2.4.2. Equation 5: Side-effects of closest element
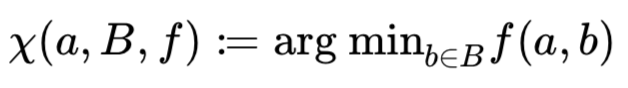
Equation 4 (page 48): Function to determine closest element (used in Eq 5)

d(red, black) < d(green, black). But green is intuitively more similar to black.
Possible solution: normalize points to "central point"
2.7. Better than random not sufficient to claim realism
- Root problem: Testing realism is tricky (impossible?).
- No alternative algorithms → random generation is the "best" alternative.
- Alternative method: user studies. (people's capabilities are questionable)
3.2. What is stored?

- Initial snapshot
- Aggregated deltas
- Indexes per delta
- Precalculated addition counts
- Relative positions
- Local change flags
3.3. Why use OSP index for S?O queries?
No filtering required in OSP index compared to SPO index.
Query: S2 ? O2
| O | S | P |
| O1 | S1 | P1 |
| O1 | S2 | P2 |
| O2 | S2 | P1 |
| O2 | S2 | P2 |
| O3 | S1 | P1 |
| 03 | S3 | P3 |
| S | P | O |
| S1 | P1 | O1 |
| S1 | P1 | O3 |
| S2 | P1 | O2 |
| S2 | P2 | O1 |
| S2 | P2 | O2 |
| S3 | P3 | O3 |
3.4. Relative position definition
Assumption: triples are comparable in the context of an index (SPO, POS, OSP)
T: set of all possible triples
t: triple (t ∈ T)
D: delta (D ⊆ T)
p: triple pattern (T → True ∨ False)
relative_position(t, D, p) = count{t' | t' ∈ D ∧ p(t') ∧ t' < t}
3.5. Why are local changes needed?
Required for VM queries and during ingestion.
View on one triple in a dataset:
| Version | Type | Local change? |
| 0 | Snapshot | / |
| 1 | - | F |
| 2 | + | T |
| 3 | - | F |
Queries:
- Version 1, 3: Start snapshot, filter away deletion
- Version 2: Start snapshot as-is (ignore local changes)
3.6. Local change definition
Definition on page 27 was incomplete (example in Table 9 (page 76) is correct).
Triples that revert a previous addition or deletion within the same delta chain, are called local changes.
Triples that revert a previous non-local-change (addition or deletion) within the same delta chain, are called local changes.
Implementation
3.8. Proof refers to functions, not defined
Lines 13, 14, 15, 16, 2, 3, 11, 13, 20, 21, 22 (in order of mentions)
- array.offset(n): A new array where all indexes are subtracted by n, where all negative indexes are removed.
- array.peek(): array[0]
- store.getDeletionsStream(tp, version, offsetTriple): A new stream of all stored deletion triples matching the given triple pattern for the given version occuring after the given triple.
- deletions.getOffset(triplepattern): The relative position of the given triple pattern.
- store.getSnapshot(version): Returns the snapshot of the given version.
- snapshot.query(triplepattern, offset): Returns a new stream of all triples in the given snapshot matching the given triple pattern, where the streams starts with the given offset.
- snapshot.getVersion(): The version the given snapshot was created for.
- stream.count(tp): The number of matching triples for the given triple pattern.
- stream.offset(offset): A new stream that has been advanced with offset elements.
3.12. Statistical test for hypothesis 3
- Each group (VM, DM, VQ) compared using independent two-group t-test
-
Independent because queries have different meaning within groups.
→ Different number of instantiations (e.g. VM: times number of numbers)
→ Different group sizes (dependent t-test will throw error)
- Source code
3.13. Hypothesis 3: assumptions
- Independent two-group t-test
- Requires all groups to be normally distributed
- I’ve added Kolmogorov-Smirnov to test normality → confirmed
- Commit
3.14. Offset for DM not explained
- Unlike VM and VQ, no efficient algorithm
- Naive algorithm: offset(n): call .next() n times
- Offset not in constant time (As seen in Fig. 34, page 96)
-

Fig 34. DM offset execution times.
- Source code
- Possible improvement: extend relative positions for DM (storage increase)
3.15. How is Table 9 stored in a B+tree?
3.16. Why only a single delta chain?
4.2. Comunica configs
-
@comunica/actor-init-sparql: SPARQL query config (89% test suite)
140 packages, 3 main categories:
- SPARQL query operators: quad pattern, slice, join, filter, ...
- RDF parsing and serialization
- Source handlers, LD, TPF, SPARQL, RDFJS, HDT, OSTRICH
@comunica/actor-init-sparql-file: Queries local RDF files@comunica/actor-init-sparql-rdfjs: Queries in-memory RDFJS datasets@comunica/actor-init-sparql-hdt: Queries HDT files@comunica/actor-init-sparql-ostrich: Queries OSTRICH datasets- LDflex config: Query operators needed for LDflex, Solid HTTP actor
- GraphQL-LD config: Query operators needed for GraphQL-LD, Solid HTTP actor
- rdf-parse: RDF parsing package
- rdf-dereference: RDF dereferencing package
4.4. Federation
-
Algorithm from TPF client (Triple Pattern Fragments: a Low-cost Knowledge Graph Interface for the Web, Verborgh et. al.)
- Source selection at query time
- Generalization: TPF interfaces → sources triple/quad pattern access
- Drill down queries to quad pattern level
- At quad pattern level: union across all sources
- Optimization: cache empty patterns
4.6. Comunica adoption
- Researchers: mostly ourselves, Nantes attempted → more docs and tutorials
- Developers from Solid community
-
Stats:
- GitHub stars: 112
- GitHub usages: 88
- GitHub forks: 17
- NPM: ~1000 weekly downloads
- Issues: 594 (77 open)
- Contributors: 14
- Used in abstraction layers: LDflex, GraphQL-LD
- Usage for SPARQL 1.2
- Collaboration with WU Vienna
5.7. Assumptions and use cases
Assumptions:
- Data volatility is predictable
- Data volatility is 10 seconds or slower
Use cases:
- Versioned datasets (DBpedia)
- Sensors emitting at fixed rates (temperature)
- Aggregations of sensor data (hourly, daily, ...)
- Radio broadcast playlists
Out of scope:
- Lightning strikes
- Counting cars in traffic
- Tweets
6.3. Links to other people's work
Within lab:
- PoDiGG: Linked Open Data Interfaces
- Versioning: Master thesis student(s)
- Querying: Planner.js, LDflex, KNoWS website
- Query evolving: Linked Open Data Interfaces
- Future: Mappings, reasoning
Outside lab:
- Versioning: NII, Japan (Hideaki Takeda)
- Querying: WU, Austria (Sabrina Kirrane, Axel Polleres)
- Querying: Inrupt